

任务目标:金价数据的收集、预处理和准备
1. 数据收集
1)使用yfinance库来获取历史金价数据。yfinance 是一个方便的库,可以从Yahoo Finance下载金融市场数据。
1 | import yfinance as yf |

似乎出现了一些问题…
从错误信息来看,yfinance在尝试获取GC=F(Gold Futures,黄金期货)数据时遇到了连接超时的错误,并且下载失败了。这个问题可能是由网络连接问题或Yahoo Finance服务器的暂时性问题引起的。
解决方法
- 检查网络连接: 确保网络连接正常,尤其是在尝试访问外部API时。你可以尝试在不同的网络环境下再次运行代码。(我是OK的~)
- 尝试其他数据源: 如果
yfinance一直无法正常工作,考虑使用其他数据源,比如Quandl,或者直接从金融数据网站下载数据。(这个换赛道其实也行,但是不解决当前问题内心当然会OB~) - 增加超时时间: 可以尝试增加
yfinance请求的超时时间,以防止连接超时问题。虽然这是一个临时解决方案,但有时可能有用。 - 直接从其他站点下载: 如果问题持续,那就简单粗暴一点,直接手动从一些网站(如Yahoo Finance:https://finance.yahoo.com/quote/GOGL/)直接下载数据,并将其保存为CSV文件,然后继续数据预处理步骤,欸嘿,主打一个弯道直达~
首先,尝试使用以下代码增加超时时间:
1 | import yfinance as yf |
如果还是不行,那就试试简单粗暴的办法吧:
替代方法 1: 手动下载数据
访问Yahoo Finance:
打开 Yahoo Finance。
搜索“Gold Futures”或直接搜索
GC=F。
在页面中找到历史数据,选择你需要的时间范围(比如2010年至今),然后下载为CSV文件。
(找了半天没看到有download按键,而且网页还增加了反爬虫技术,tnnd
,那就直接把整个网页保存下来进行解析简单粗暴)保存网页:
在网页空白处右键选择“另存为”
保存为html文件后;
开始解析文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34from bs4 import BeautifulSoup
import pandas as pd
# 读取保存的HTML文件
with open('/mnt/data/Micro Gold Futures,Dec-2024 (MGC=F) Stock Historical Prices & Data - Yahoo Finance.html', 'r', encoding='utf-8') as file:
soup = BeautifulSoup(file, 'html.parser')
# 尝试查找包含历史数据的表格
table = soup.find('table')
if table is None:
print("未找到数据表格,请检查HTML文件的结构。")
else:
# 如果找到了表格,继续提取数据
headers = []
if table.find('thead'):
headers = [th.text.strip() for th in table.find('thead').find_all('th')]
rows = []
for tr in table.find('tbody').find_all('tr'):
cells = [td.text.strip() for td in tr.find_all('td')]
if len(cells) > 1: # 过滤掉空行
rows.append(cells)
# 检查是否成功提取数据
if not headers or not rows:
print("未能提取到任何数据,请检查表格内容。")
else:
# 将数据转换为DataFrame
gold_data = pd.DataFrame(rows, columns=headers)
# 保存为CSV文件
gold_data.to_csv('gold_price_data_extracted.csv', index=False)
print("数据已成功提取并保存为 gold_price_data_extracted.csv 文件。")
数据提取完成!
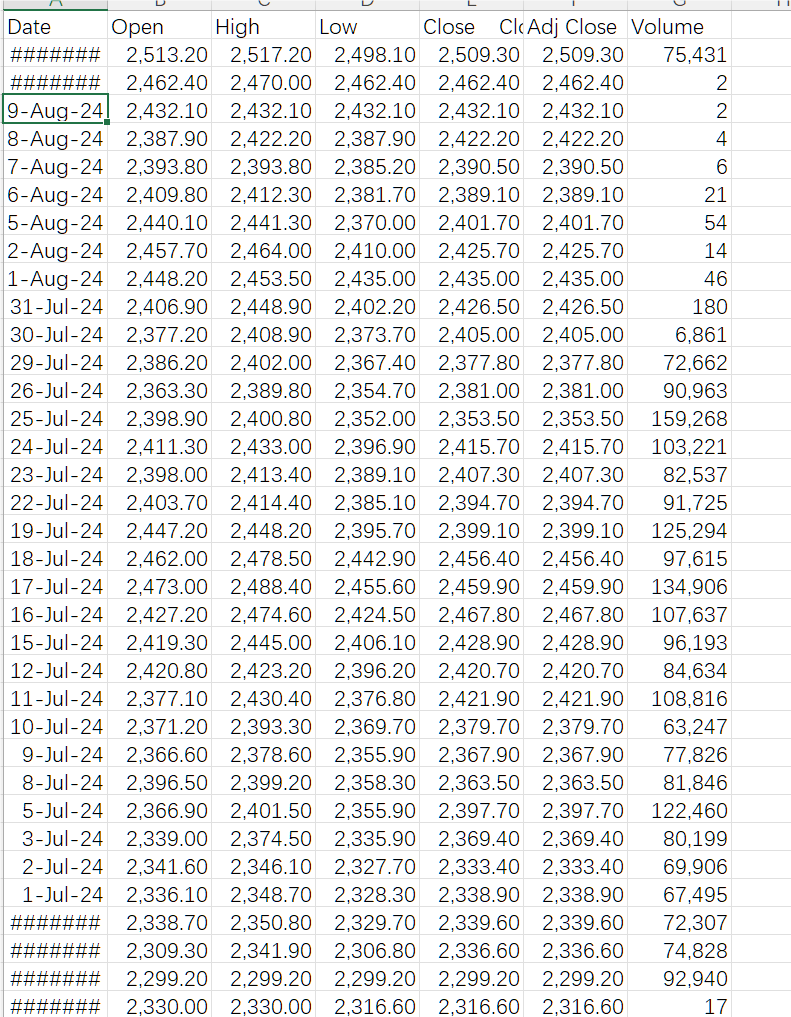
2. 数据预处理
数据收集完毕后,我们需要对数据进行一些预处理。
1.数据检查和清洗
- 检查数据格式:确保日期列是
datetime类型,价格数据是数值类型。 - 处理缺失值:检查并处理任何缺失数据。
- 删除无关列:如果有无关的列(如“交易量”等),可以选择删除。
2. 特征工程
- 生成技术指标:添加一些常用的技术指标(如移动平均线、相对强弱指数RSI、MACD等)。
- 生成目标变量:创建模型的目标变量,即未来三天的金价变化。
3. 数据标准化/归一化
- 对特征进行标准化或归一化处理,以提高模型训练的效果。
- 检查数据格式:确保日期列是
1 | import pandas as pd |
成功数据净化:
下期预告:
下一步:模型设计与训练
我们将从以下几个方面着手:
- 数据集划分:将数据分为训练集和测试集。
- 模型选择:设计一个合适的深度学习模型(例如LSTM或GRU)来处理时间序列数据。
- 模型训练:使用训练集对模型进行训练,并使用验证集进行超参数调优。
- 模型评估:在测试集上评估模型的性能,使用指标如均方误差(MSE)等。
- 本文作者: Anderson
- 本文链接: http://nikolahuang.github.io/2024/08/10/从零开始训练一个神经网络之二:数据收集和准备/
- 版权声明: 转载请注明出处,谢谢。