

在上期我们实现了多算法训练的不同的模型来对金价走势进行预测,可以看到LSTM得到的模型拟合的精度最高;
我们后续提出了两个问题:
- 如何实现多算法结合的混合模型?
- 如何将得到的最佳模型进行部署和实战检验?
如何实现多算法结合的混合模型?
创建一个混合模型的思路是将多个模型的预测结果结合在一起,以期望获得比任何单一模型更好的性能。这通常通过以下几种方法来实现:
- 加权平均法:根据各个模型在验证集上的表现,对它们的预测结果进行加权平均。权重可以基于每个模型的均方误差(MSE)反向设置,MSE越低的模型权重越高。
- 堆叠(Stacking):将多个模型的预测结果作为输入,使用一个元模型(如线性回归、决策树、SVM等)来学习如何最佳地组合这些预测。
- 投票法:对于分类任务,混合模型也可以通过多数投票的方法来确定最终预测。
当前场景中,我们可以用加权平均法来构建一个混合模型。这是因为主要关注的目标“金价”是时间序列,且使用的模型都是回归模型。
实现思路
- 训练多个模型:分别训练LSTM、GRU、CNN、XGBoost、RandomForest、SVM、MLP等模型,并获取它们在验证集上的预测结果和对应的MSE。
- 计算加权平均:使用每个模型的MSE反向作为权重,对它们的预测结果进行加权平均。MSE越低的模型,其预测结果权重越高。
- 生成最终预测:对测试集进行加权平均预测,并计算最终的MSE。
以下是代码的实现:
1 | import tensorflow as tf |
运行的结果如下:
1 | 2024-08-18 22:45:34.472344: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`. |
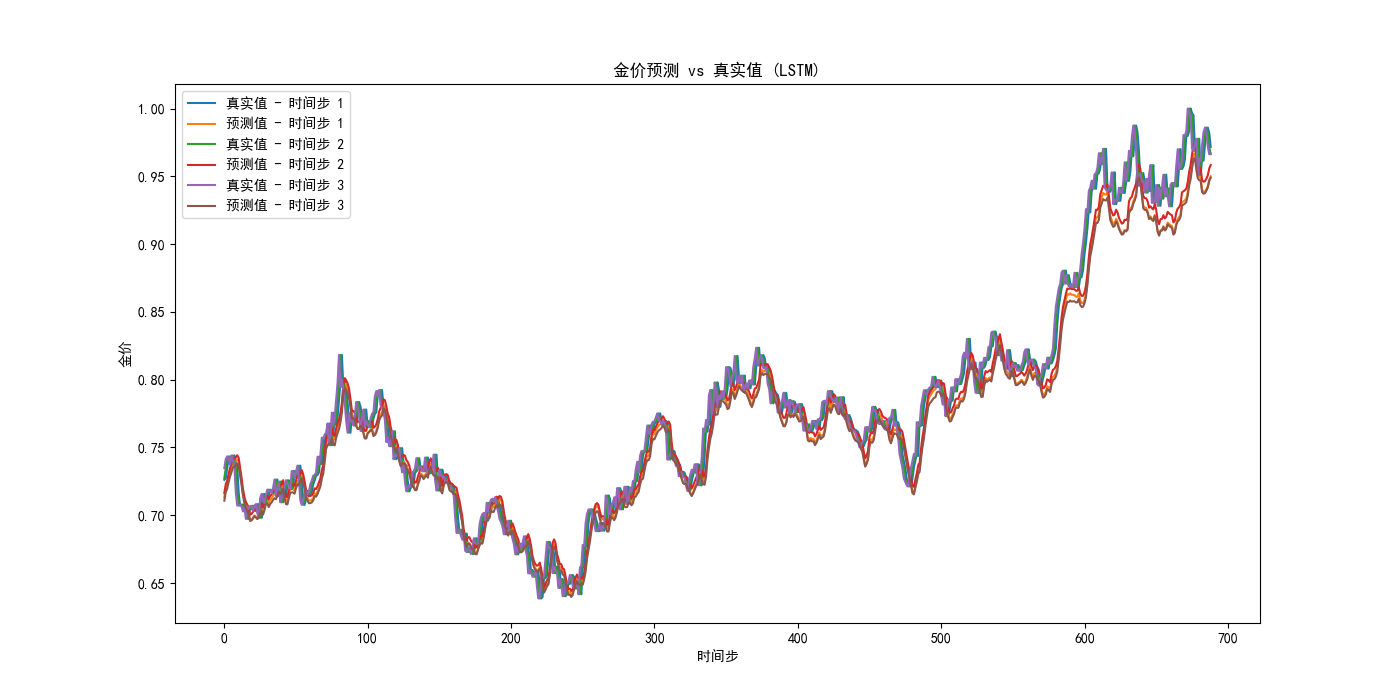
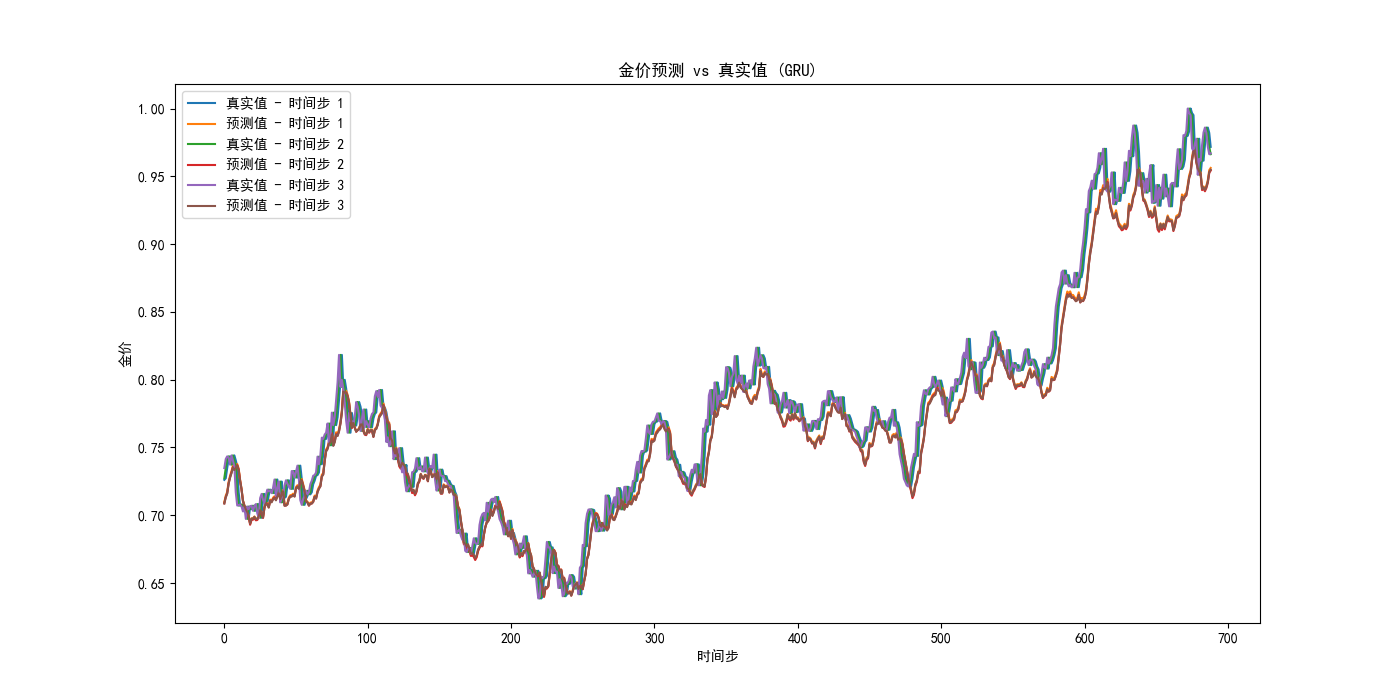
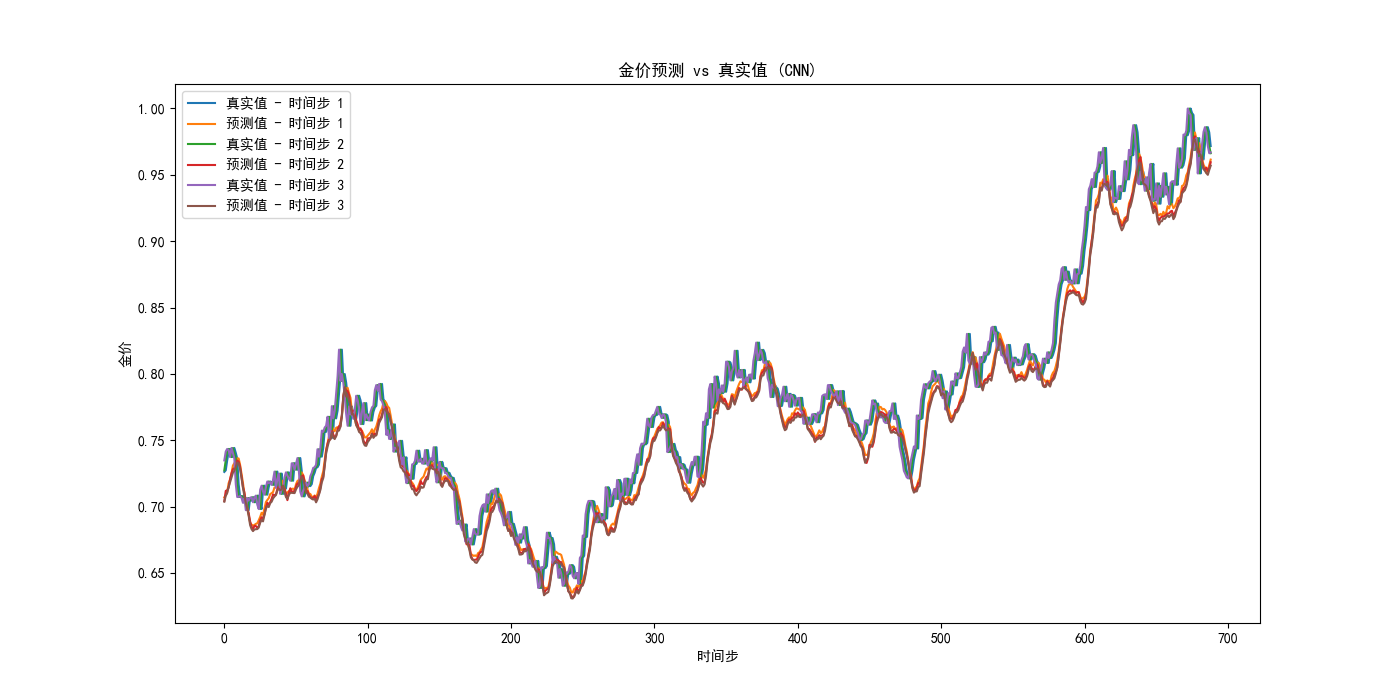
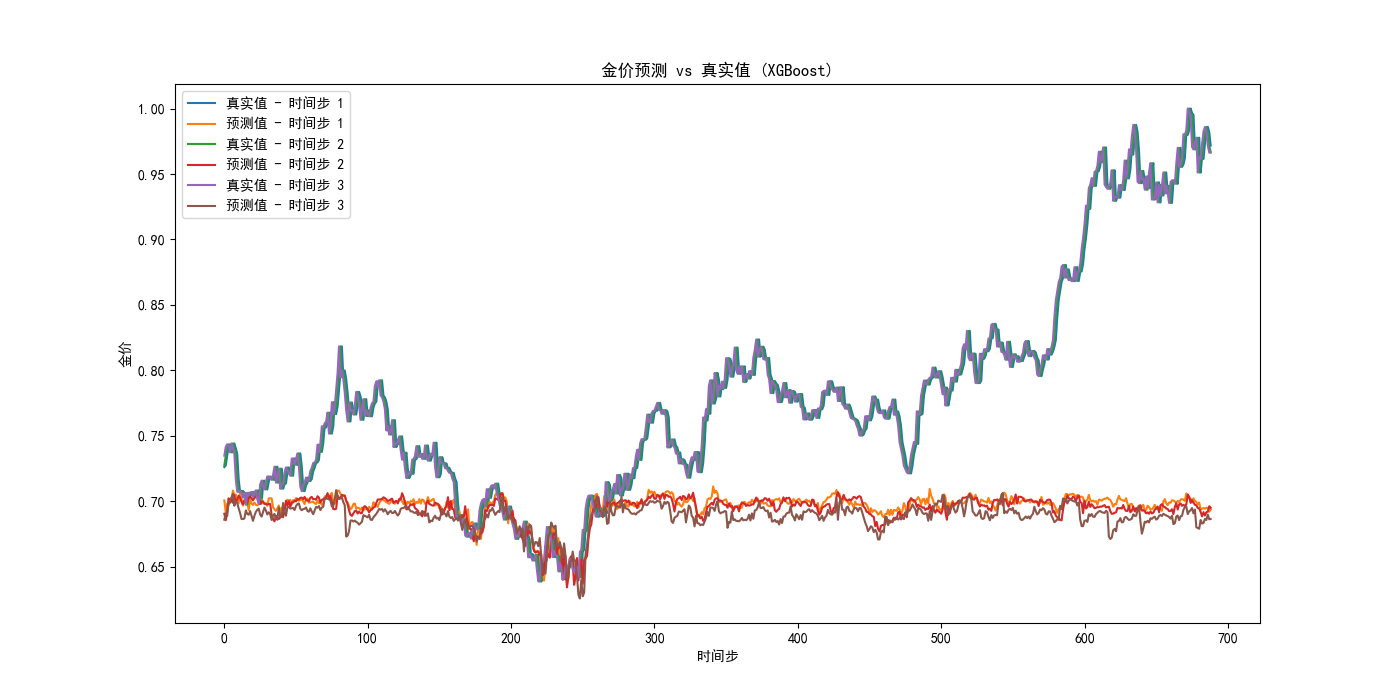
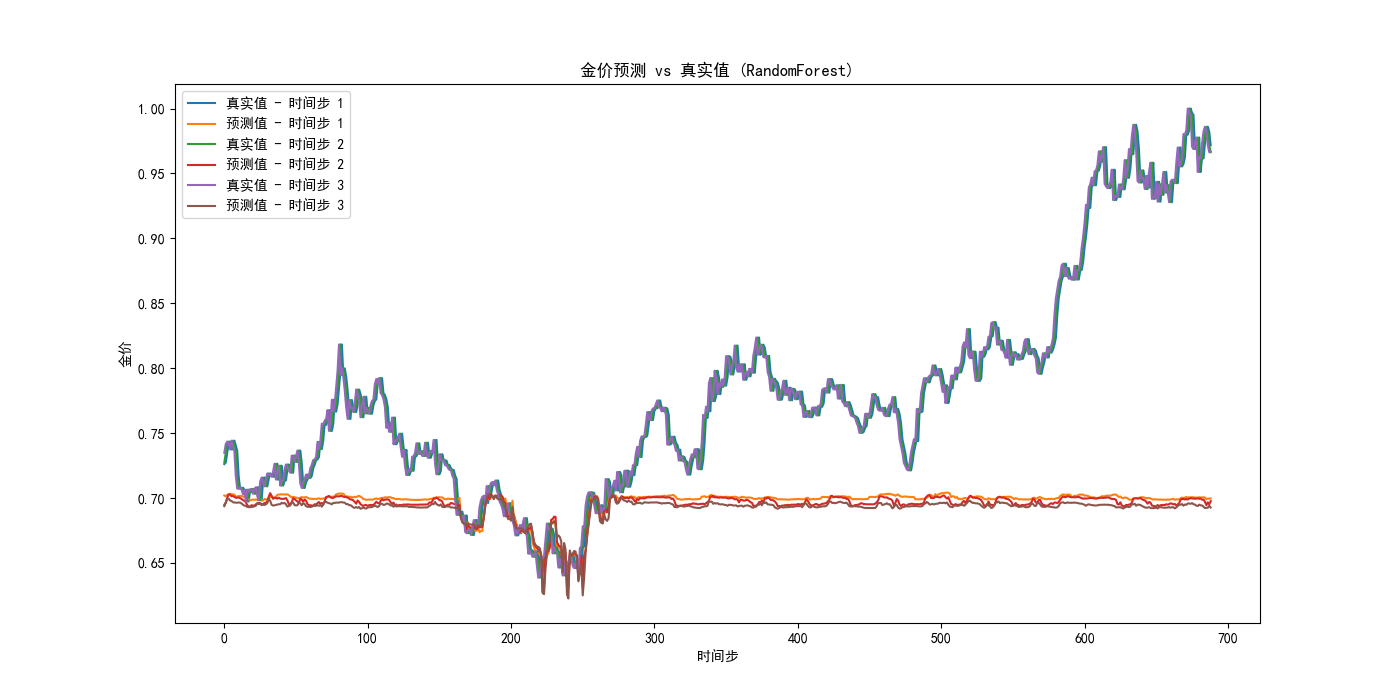
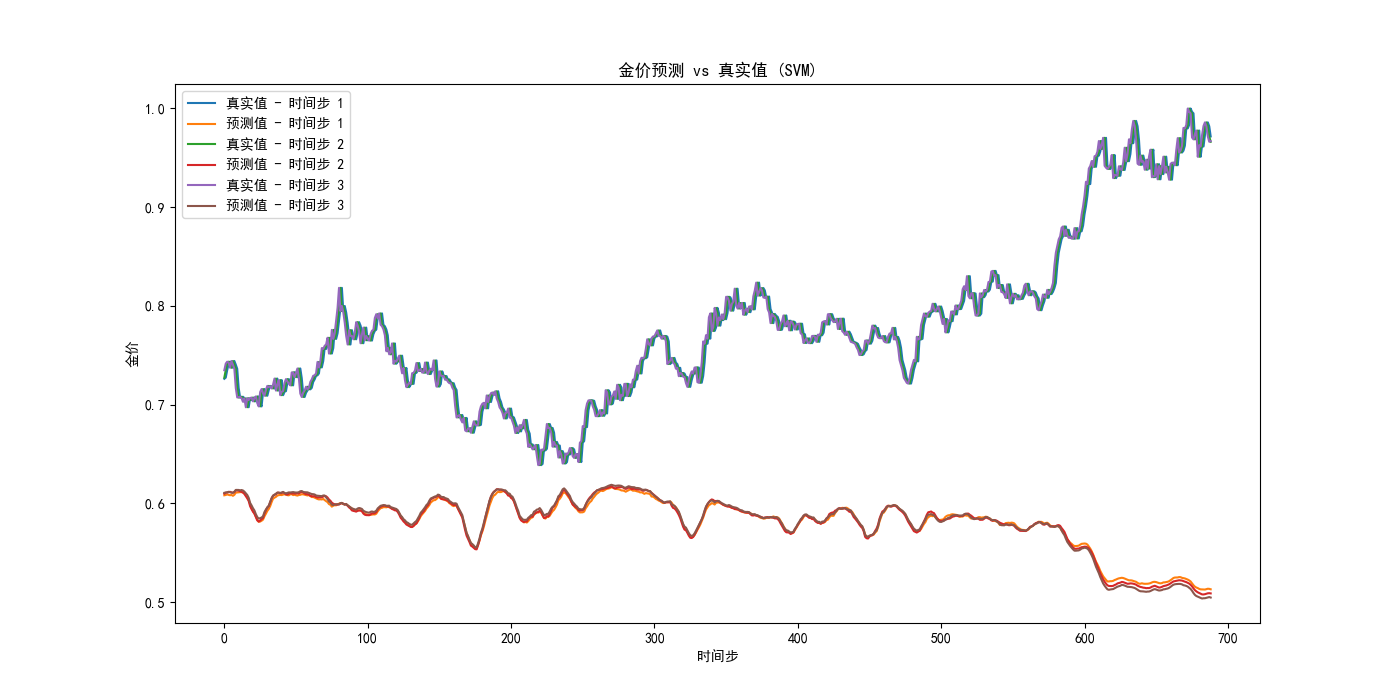
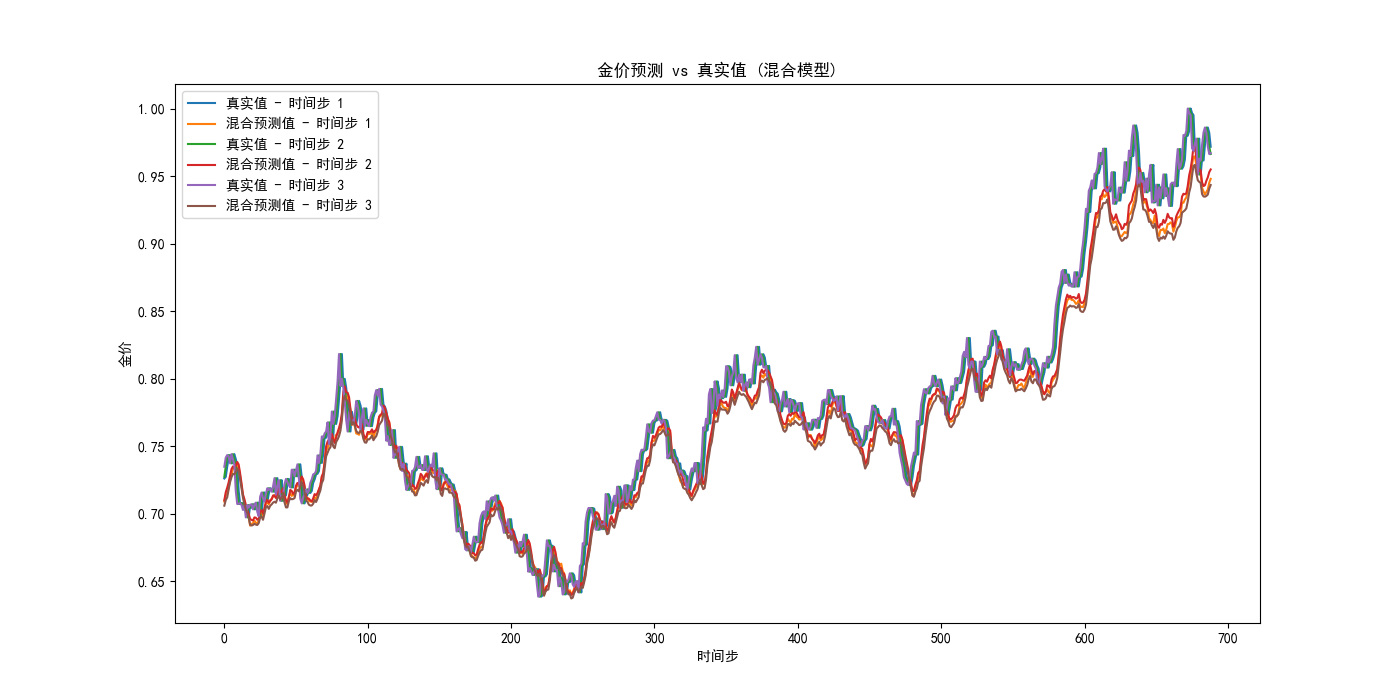
我们可以注意到:
- 运用LSTM设计的模型在测试集上的均方误差: 0.00027118924039005093,而我们最终的混合模型的均方误差: 0.0003560467854642135,反而比LSTM大;
- 模型训练的结果波动幅度比较大(经过本人多次测试);
解决上述问题的实现思路和方法:
混合模型的表现有时可能不如某个单独模型的原因可能包括以下几点:
- 权重分配:在混合模型中,模型的预测结果是基于每个模型的均方误差(MSE)进行加权的。如果一个模型的预测误差相对较小,它的权重就会更大。然而,如果这些模型的预测结果具有较大的方差,即使一个模型的MSE较小,整体的加权平均可能并不会显著提升预测精度。
- 模型之间的相似性:如果多个模型的预测结果非常相似,那么组合它们并不会显著提高性能。在这种情况下,混合模型的表现可能接近于最好的单个模型。
- 混合策略的局限性:当前的混合策略只是简单地基于MSE进行加权平均,没有考虑更复杂的混合策略,例如非线性组合、堆叠模型(stacking),这些更复杂的方法可能会捕捉到单个模型未能捕捉到的模式,从而提高整体模型的表现。
- 模型多样性不足:混合模型的效果依赖于不同模型之间的多样性。如果模型之间的多样性不足(即它们预测出的结果过于相似),混合模型的效果可能不会显著提升。
可能的解决方法
- 尝试其他混合策略:除了简单的加权平均,你可以尝试其他混合方法,例如堆叠(stacking),其中一个元学习器(如线性回归、神经网络)学习如何组合不同模型的预测结果。
- 增加模型的多样性:通过加入更多不同类型的模型,或者调整现有模型的超参数,可以增加模型的多样性,从而提升混合模型的效果。
- 模型选择:有时,简单的选择表现最好的单一模型可能比混合所有模型效果更好。你可以通过更多的验证和交叉验证来决定是否需要混合模型。
- 手动调整权重:尝试对各个模型的权重进行手动调整,而不仅仅依赖于MSE来进行加权。手动权重调整可以基于经验或者通过优化方法找到最佳的权重组合。
尝试使用其他混合方法,例如堆叠(stacking),学习如何组合不同模型的预测结果、调整现有模型的超参数增加模型的多样性
- 整体框架和模块设计
- 数据预处理模块 (
data_preprocessing_main): 这一部分代码从CSV文件中加载数据,并进行清洗、标准化、技术指标生成等处理,生成用于模型训练和测试的数据集(X_train,X_val,X_test,y_train,y_val,y_test)。 - 模型构建模块 (
build_model): 该函数根据传入的模型类型 (model_type) 构建不同类型的模型。支持的模型类型包括神经网络模型(LSTM,GRU,CNN)和传统机器学习模型(XGBoost,RandomForest,SVM,MLP)。对于神经网络模型,使用Keras框架进行构建,并返回编译好的模型;对于传统机器学习模型,返回的是模型实例列表,每个列表中的模型用于预测一个时间步。 - 模型评估模块 (
evaluate_model): 该函数评估训练好的模型在测试集上的表现,计算并打印均方误差(MSE),并绘制模型的预测结果与真实值的对比图。神经网络模型直接通过model.predict生成预测值,而传统机器学习模型则针对每个时间步分别进行预测并组合。 - 堆叠模型模块 (
stack_models): 此函数实现了使用堆叠方法来组合多个模型的预测结果。对于每个时间步,堆叠模型结合了来自不同基础模型的预测结果,并使用线性回归作为初级学习器,最后通过随机森林回归器作为终极学习器进行堆叠预测。 - 模型搜索与混合模块 (
model_search): 这是核心函数,负责搜索最优模型。函数遍历不同模型类型,分别训练并评估每种模型的性能。评估完所有模型后,调用stack_models函数对模型进行堆叠组合。最后输出最优单一模型及其均方误差,同时输出堆叠组合模型的均方误差。
- 数据预处理模块 (
- 代码流程
- 数据生成: 通过
data_preprocessing_main函数生成训练集、验证集和测试集的数据。 - 模型搜索与训练:
model_search函数遍历所有指定的模型类型(包括神经网络模型和传统机器学习模型),为每种模型训练并评估其在测试集上的表现。 - 堆叠模型组合: 使用堆叠方法对所有模型进行组合预测,并计算组合模型的均方误差。
- 模型保存: 将最优的单一模型保存为HDF5格式,便于后续使用。
- 数据生成: 通过
- 模型混合策略
- 多模型训练: 每种模型都独立训练,并在测试集上进行评估。
- 堆叠策略: 对不同模型的预测结果进行堆叠,通过线性回归和随机森林等方法来学习如何最优地组合这些模型的预测,得到最终的组合模型预测结果。
- 主要亮点
- 多样化的模型选择: 支持多种神经网络模型(LSTM、GRU、CNN)以及传统机器学习模型(XGBoost、RandomForest、SVM、MLP)。
- 堆叠方法的应用: 通过堆叠多种模型的预测结果,实现了不同模型的优势互补,旨在提高最终预测的准确性。
- 代码的灵活性和可扩展性: 使用统一的框架处理不同类型的模型,使得代码具有很高的可读性和可维护性,便于进一步扩展。
代码实现:
1 | import tensorflow as tf |
输出结果:
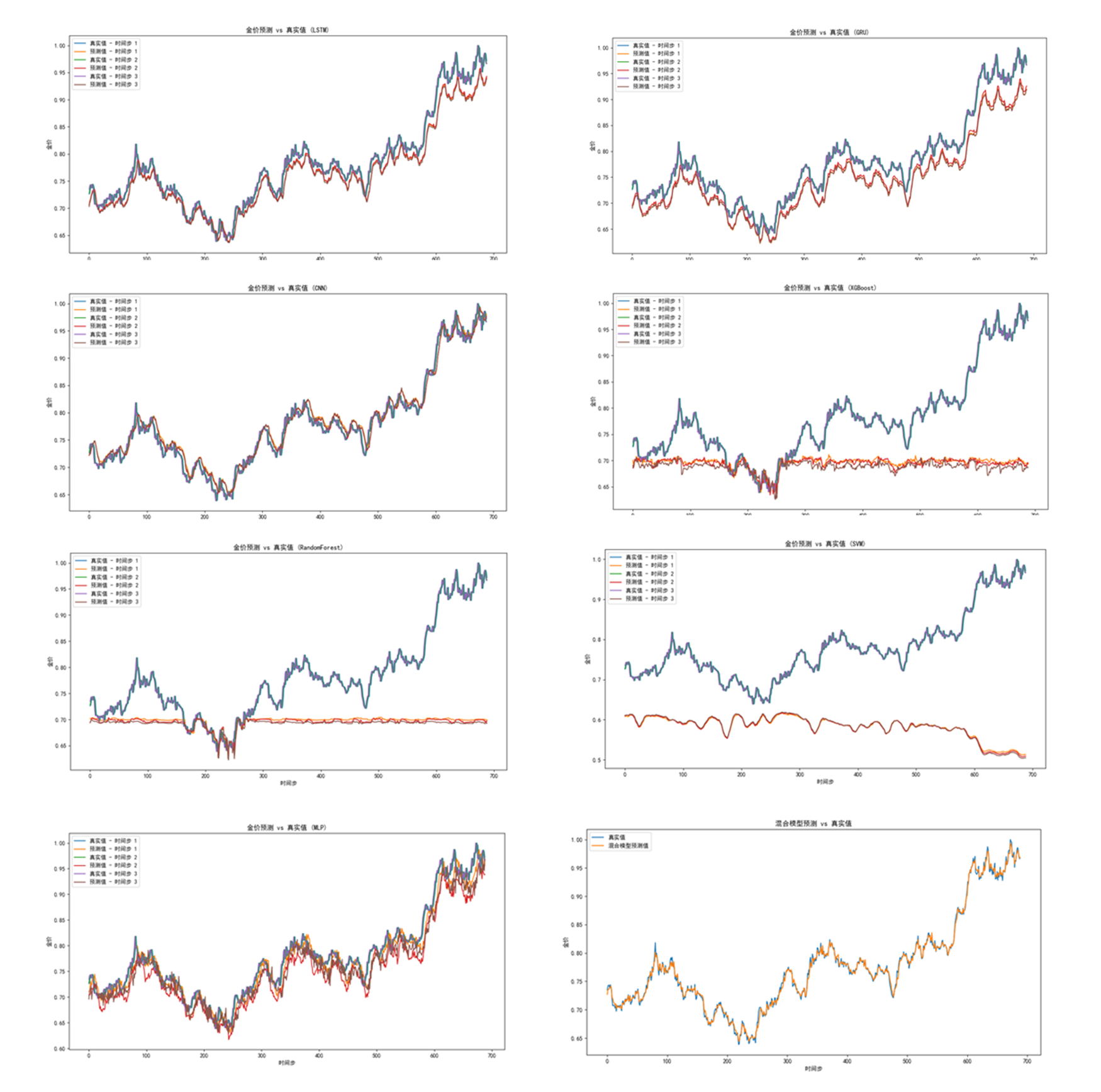
1 | 2024-08-19 00:32:57,653 - INFO - 数据加载完成 |
这样我们就得到了最佳拟合的混合模型stacked_model.joblib,基准测试显示精度非常高,与真实值几乎一致!!!
下一期内容:
模型的部署和上线。
- 本文作者: Anderson
- 本文链接: http://nikolahuang.github.io/2024/08/18/从零开始训练一个神经网络之四:模型调优和部署/
- 版权声明: 转载请注明出处,谢谢。